Phoenix pVM-based Virtual Machine Monitors

Passionate about software development and architecture, web and cloud technologies, as well as game development.
1. Introduction
Cloud Computing (CC) already plays a major role in providing services throughout the internet. Two hundred seventy billion US dollars were spent by companies worldwide in 2020 for cloud services [2] . The cloud provides users with access to computing resources of different kinds that can be deployed to data centers around the world. Only the demanded resources are billed, and resource requirements can be changed at any time. The National Institute of Standards and Technology (NIST) describes CC as “[…] a model for enabling convenient, on-demand network access to a shared pool of configurable computing resources (e.g., networks, servers, storage, applications, and services) that can be rapidly provisioned and released with minimal management effort or service provider interaction.” [3].
More and more companies invest in the migration to the “cloud” because of the various advantages over conventional computing solutions. The benefits include, but are not limited to:
- Elasticity: Applications scale up or down dynamically to any workload
- Scalability: Complex infrastructure scales up without additional work
- Availability: Services are available at any time with little latency from around the world
Another very important principle is Fault Tolerance (FT), which describes the ability to continue operating without interruption when a fault occurs. Two common methods to handle all kinds of faults happening in the infrastructure and application are replication and redundancy: When applying the replication strategy, the state of an application is replicated to multiple machines. As soon as a replica becomes unavailable, requests are routed to a different machine with a working application instance. This technique can also be used to scale for different amounts of workload. Redundancy is a more traditional technique, which describes the concept of having backup systems that take over in case of a fault occurring.
While with the aforementioned strategies, FT can be achieved in cloud architectures, it is still desirable to minimize the probability of faults happening in the first place. When fewer faults occur, fewer backup or replication systems are needed since fewer systems can fail at the same time. Also, faults may still affect users with service interruptions or data loss. Therefore it is in particular interest to the customer to have his infrastructure running with as few faults as possible.
Faults can either occur in the application of the customer using the cloud services or in the cloud infrastructure, which is provided by the cloud vendor. While the customer is responsible for aspects like FT in his own applications, the cloud vendor is responsible for the infrastructure. In the Service Level Agreement (SLA), the cloud vendor commits to a specific availability of its services, including penalties in the case those commitments were not met. Since cloud service providers want to offer high availability metrics to protrude against the competition without running into the risk of paying penalties, they are motivated to optimize their infrastructure systems for FT.
Cloud resources can be allocated within minutes or even seconds because the hardware is already located and waiting to be claimed at some data center. CC resources are often provisioned on-demand as virtualized machines instead of dedicated hardware. This allows to automate the deployment process and make it more affordable since those resources are shared with other users.
Mvondo, Tchana, Lachaize, et al. describe a novel FT approach (the source code is available on www.github.com/r-vmm/R-VMM) to provide increased resilience for so-called “pVMs” (not to be confused with the concept of “process Virtual Machines”) and apply it to make the Xen platform more fault-tolerant. In a privileged Virtual Machine (pVM)-based architecture, the hypervisor (aka. Virtual Machine Monitor (VMM)) is split into two components: The bare-metal hypervisor and the pVM. A pVM is a virtual machine that has direct access to the hardware and takes over some of the functionality (like handling device drivers) of the hypervisor. The authors modify the Xen pVM to build a resilient version by working through the three design principles disaggregation, specialization and pro-activity [1]. The work by these authors is summarized and discussed in this paper.
The remainder of this paper is organized as follows. The next section, Section 2, gives an introduction to those so-called pVMs. Their workings and purpose will be explained. Following in Section 4, the four unikernels, their fault model, and implementation will be discussed. The benchmark results of Mvondo, Tchana, Lachaize, et al.’s solution are presented and compared against others in Section 6. Similar approaches will be analyzed next, in Section 5. This paper concludes with a discussion from the author’s perspective in Section 7, followed by the conclusion in Section 8.
2. Privileged Virtual Machines
A is a special guest Virtual Machine (VM) supporting the VMM in performing non-critical tasks. Popular hypervisors like Xen and VMware ESX use this concept to run external software (like Linux device drivers) in a less critical and less privileged environment [4]. This approach provides a separation between the code of the VMM and external software. Such a pVM (also called “dom0”, or “Domain0”) is often used to run device drivers for the physical hardware as well as serving as the administrative interface to the system [4]. The VMM’s area of responsibility is then reduced to tasks like scheduling and memory management [4]. The other guest VMs (or “domU”) will then connect to the pVM instead of the hypervisor directly. Such an architecture is visualized in Figure 1.
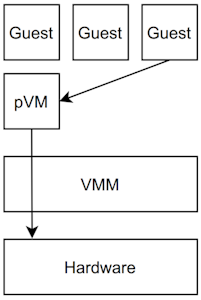
Figure 1: The virtualization architecture when using the pVM approach. The pVM and guest VMs are virtualized by the VMM. Communication, to e.g. access the drivers, is done through the pVM (exemplary visualized by the arrows).
Because the size of the source code is greatly reduced and code containing potential faults is removed, software faults may occur less often by applying the pVM strategy. Also, less time is spent executing that code, which lowers the chance of being affected by a hardware fault. This outsourcing of tasks to the pVM entails that a fault is less likely to occur in the VMM.
While using this strategy to create a more robust VMM comes with many advantages, this also introduces the pVM as a new single point of failure. Since the pVM will run on a fully-fledged Operating System (OS), possibly with several external applications running in user space, the chance of a fault happening increases significantly. However, because of the already discussed advantages of a pVM, it should be easier to handle such fault in software running on an OS.
3. Xoar Project
Colp, Nanavati, Zhu, et al. split the monolithic pVM architecture of the Xen platform into nine different classes of least-privilege service VMs to make it more secure. This approach, called “Xoar”, uses a microkernel for each service. They achieved this while maintaining feature parity and with little performance overhead [5].
Microkernels use a minimal kernel that provides an interface for a larger part of the kernel that implements the full functionality needed to run applications. In contrast to the monolithic architecture (used by Linux), the kernel space is rather small, which increases security and stability.
Xoar was designed with three goals in mind [5]:
- Reduce privilege: A service only has access to the most minimal interfaces it requires to function. This limits the attack surface.
- Reduce sharing: Shared resources should only be used when necessary and be made explicit. This allows for policies and proper auditing.
- Reduce staleness: Services should only run while they actually perform a task. This limits attacks to the lifetime of a task.
The decomposition of the pVM allows for new measures that follow these goals to increase security and stability. For example, there is a service VM that handles the boot process of the physical machine. This isolates the complex boot process and the required privileges. This VM is destroyed after the boot process is finalized. They also implement microkernels to record secure audit logs of all the configuration activities. Additionally, they implement a microreboot strategy to lower the temporal attack surface. This requires potential attackers to at least attack two isolated components in order to compromise the service [5].
This approach of splitting the pVM into smaller isolated VMs is also used in the work from Mvondo, Tchana, Lachaize, et al. [1] that is presented in the following section. Their work is largely based on the Xoar project and their disaggregation of the pVM.
4 Phoenix pVM-based VMM (PpVMM)
The FT strategy presented by Mvondo, Tchana, Lachaize, et al. is called Phoenix pVM-based VMM (PpVMM) and builds on three core principles [1]:
- Disaggregation: Each pVM service is launched inside it’s own isolated unikernel.
- Specialization: Each unikernel uses a strategy to handle faults that is tailored to the service run by that unikernel.
- Proactivity: Each service implements an active feedback loop that detects and automatically repairs faults.
A “unikernel” is a small isolated system that runs a process in a single address space environment with a minimal set of preselected libraries that are compiled together with the application to a single fixed-purpose image. This image, which is based on a unikernel OS runs directly on the hypervisor, similar to a VM. Mvondo, Tchana, Lachaize, et al. disaggregate the functionality of the Xen pVM into four independent unikernel VMs: net_uk, disk_uk, XenStore_uk, and tool_uk [1].
The overall architecture of the PpVMM approach. The global feedback loop runs in the UKmonitor unikernel and monitors the the four unikernels and their heartbeats (red arrows) of the pVM or dom0 (also known as “Domain Zero”). When a VM running in domU (the unprivileged domains) then wants to connect to the Network Interface Controller (NIC) it connects to the driver running on the pVM (blue arrow).
net_uk implements the unikernel that hosts both the real and para-virtualized network drivers. Figure 2 shows the examplary path of a request from the guest OS, through net_uk to the NIC. disk_uk is similar to net_uk and provides the storage device drivers. Because of its similarity, the authors of the original paper choose not to discuss it in their work. XenStore_uk is the unikernel responsible for running XenStore, which is a database for status and configuration data shared between the VMM and guest VMs. tool_uk provides VM administration tools. Those unikernels will be discussed in detail in the next sections.
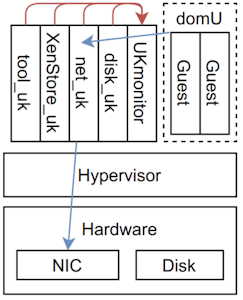 Figure 2: The overall architecture of the PpVMM approach. The global feedback loop runs in the UKmonitor unikernel and monitors the the four unikernels and their heartbeats (red arrows) of the pVM or dom0 (also known as “Domain Zero”). When a VM running in domU (the unprivileged domains) then wants to connect to the network interface controller (NIC) it connects to the driver running on the pVM (blue arrow).
Figure 2: The overall architecture of the PpVMM approach. The global feedback loop runs in the UKmonitor unikernel and monitors the the four unikernels and their heartbeats (red arrows) of the pVM or dom0 (also known as “Domain Zero”). When a VM running in domU (the unprivileged domains) then wants to connect to the network interface controller (NIC) it connects to the driver running on the pVM (blue arrow).
Each unikernel uses a feedback loop that uses probes to detect faults and actuators to repair those faults. Some unikernels are made up of several components, which also use feedback loops themselves [1]. Those feedback loops are implemented outside the component to make them independent from faults occurring inside the component.
The feedback loop of each component is coordinated by a global feedback loop (running in the “UKmonitor” unikernel). Since the failure of one component could affect others (that depend on the failing component) and lead to concurrent failures in other components, a certain repair order is required. This repair order is embedded in the VMM as a graph and represents the dependencies between the different unikernels. Using this repair order, the source of the concurrent failure can be detected and be repaired if all services that the unikernel depend on are healthy again. The work by Mvondo, Tchana, Lachaize, et al. assumes that the hypervisor itself will not fault (because of state-of-the-art FT countermeasures). Therefore they implement the global feedback loop inside the VMM as seen in Figure 2 [1].
The pVM is connected to a data center management system, like OpenStack Nova because some repairs cannot be done locally and require actions on a different system [1]. For example, in the case of a server running out of memory, a new scheduled VM might have to be started on a different physical server.
Implementing this pVM strategy using disaggregated unikernels requires modifying the scheduler in order to optimize performance: Each unikernel VM is marked so that they can be differentiated from the guest VMs. This marking ensures that those VMs are frequently scheduled and requires them to react within five milliseconds to heartbeat messages. The heartbeat might be skipped, though, if the unikernel recently issued an “implicit” heartbeat by exchanging other messages with the hypervisor. This prevents the CPU from switching the context to a different unikernel, just for issuing a heartbeat message while it is obviously healthy [1].
 Table 1: An overview over the pVM components that are disaggregated into their own unikernels together with the symtopms of faults that may occure during the execution.
Table 1: An overview over the pVM components that are disaggregated into their own unikernels together with the symtopms of faults that may occure during the execution.
In the following section, each unikernel implementation is explained. First, the function of the application running in the unikernel and its fault model will be presented. Right after, the FT solution will be discussed in detail. An overview of the unikernels and their fault symptoms can be seen in Table 1.
4.1. NIC Driver (net_uk)
In the Xen virtualization, the NIC driver resides in the pVM and is exposed using the so-called “NetBack” component. It enables communication with the “NetFront”, which acts as NIC driver in the guest OS in domU.
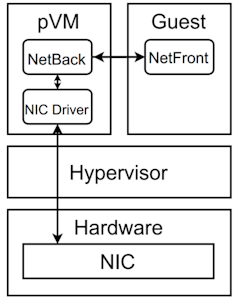
Figure 3: The network driver components when using the pVM architecture. The communication path is shown by the black arrows.
The architecture of the network driver in the Xen platform can be seen in Figure 3. The NetFront is the network driver in the guest OS and communicates with the NetBack. The NetBack uses the NIC driver in the pVM to talk with the physical NIC.
The net_uk unikernel embeds the NIC driver as well as the NetBack as. This unikernel forwards requests between the guest VMs and the VMM.
A fault in those components or the unikernel itself can lead to unresponsiveness, which has to be mitigated. The FT solution can detect failures at two levels: Fine-grained failures like NetBack and NIC failures, as well as coarse-grained failures like the whole unikernel failing. Mvondo, Tchana, Lachaize, et al. [1] assumes that such faults will not corrupt the low-level data structures of the kernel [1].
Faults in the NIC driver are handled by an approach similar to the “shadow driver” solution by Swift, Annamalai, Bershad, et al. [6]. The NetBack is modified to buffer requests between the NetBack and NetFront (running in the guest VM), in case the NIC driver becomes unresponsive. Such unresponsiveness of the NIC driver is determined by the hypervisor by recording the timestamps of the messages and detecting a timeout. This triggers the recovery process of the driver. The hypervisor also monitors the shared ring buffer index of the NetBack and NetFront. Should the index of the private buffer of the NetBack differ from the shared one, a fault it the NetBack is to be assumed and the NetBack reloaded.
Inspired by the work of Jo, Kim, Jang, et al. [7], the entire unikernel failing is detected by monitoring all buffers and calculating their lag. Since this only works when actual communication messages are exchanged and the buffer is used, a heartbeat mechanism, controlled by the VMM is introduced [1].
4.2. Metadata Storage (XenStore_uk)
XenStore_uk runs the metadata service XenStore, which is a database for status and configuration data.
Faults, whose consequence is unavailability, can also happen in the XenStore_uk unikernel. However, XenStore_uk, being the only unikernel that is stateful, is also extradited to silent data corruptions that may be caused by bit flips, defective hardware, or malicious VMs. [1]
The specialized solution to make this unikernel fault-tolerant involves state machine replication and sanity checks. To prevent unavailability, a coordinator unikernel is introduced that manages three replicas of the XenStore_uk unikernel. The coordinator itself is also replicated. The XenStore client library is modified so that requests go to the master coordinator first. It then forwards read requests to the master XenStore_uk unikernel, which is chosen by the master coordinator. Write requests are forwarded to all XenStore_uk replicas. Heartbeats are used to detect the unavailability of a replica; in such a case, the replica is pro-actively replaced by the coordinator. Should the active master replica become unavailable, a new one is chosen by the coordinator. The master coordinator sends heartbeat messages to the VMM in order to detect a crash of both the master coordinator and its replicas simultaneously [1].
To spare net_uk from the communication path between the coordinator and other components, Interrupt Requests (IRQs) and shared memory are used instead of HTTP requests [1]. This resolves the bidirectional dependency between XenStore_uk and net_uk, which makes handling cascading failures more easily.
To handle data corruption faults, a sanity check, running in each XenStore_uk replica, computes a hash of each write message and forwards it to the coordinator. The master coordinator then checks if the hash from all replicas is the same. If that is the case, it is forwarded and stored to each coordinator replica. This hash marks the just written state as the last known uncorrupted state.
When a read message is sanity checked, the master XenStore replica calculates its hash and compares it with the last uncorrupted state from the master coordinator. If they are not equal, a recovery procedure is initialized to determine the source of corruption. If the wrong hash was submitted by the coordinator, its hash is replaced by the correct value. If it stems from the XenStore_uk master replica, the recovery process is triggered, and it is replaced by a healthy replica. This strategy is based on the assumption that for each stored piece of information, at most, one copy gets corrupted [1].
With this local FT strategy, the VMM only has to intervene when all XenStore or coordinator components fail at the same time. This case will be detected by the hypervisor thanks to the heartbeat mechanism. However, restarting the crashed components by following the above-mentioned dependency graph without relying on disk_uk will not recover the state. Therefore, additional copies of the XenStore database and uncorrupted state hashes are stored by the VMM in memory. Each replica has to update its own backup copy [1].
4.3. Management Toolstack (tool_uk)
The tool_uk hosts the Xen Toolstack, which provides a life-cycle administration toolstack. It provides startup, shutdown, migration, checkpointing, and dynamic resource adjustment functionality. The Xen Toolstack is the only component that does not run a task the whole time. Instead, it executes operations when a VM operation was requested.
Faults during those operations are already handled by the vanilla toolstack implementation of the data center management system. Nevertheless, a fault during live migrations, while the state of the suspended VM is transferred to the destination host, will result in corrupted VM on the target machine and a suspended one on the sender machine [1].
A fault is detected in a similar way to a heartbeat mechanism. Should the sender machine not receive a “acknowledge” message within a specific timeframe, the migrations are to be considered a failure. The responsiveness of the entire unikernel is detected using a regular heartbeat mechanism, which restarts tool_uk in such a case. Any case leaves the VM on the target machine in a corrupted state. To recover from these failures, the corrupted VM (and its state) is deleted, and the original VM on the seder machine is set to resume its normal operation. The migration can then be re-executed [1].
The unikernel is also set to use a different role in Xen, which limits the actual privileges of the unikernel.
5. Related Work
While there are many publications on the topic of FT in cloud-based applications, there is not as much work in the field of making the hypervisor more fault-tolerant. Nevertheless, the PpVMM approach is not the first one to disaggregate the pVM. The Xoar project [5], which was presented in Section 3 developed the groundwork for the PpVMM approach [1].
The work of Jo, Kim, Jang, et al. and their TFD-Xen [7] project inspired the PpVMM solution, too [1]. The authors focused on the reliability of the network drivers inside the pVM [7]. Their approach is fast to recover from faults since it uses physical backup NICs. However, this also results in resource waste and additional costs since further hardware is required. Their solution to detect faults by monitoring the shared ring buffers used by all NetBacks and NetFronts is used in the net_uk unikernel as presented in Section 4.0.1.
A quite different approach to detecting faults is shown in “Xentry: Hypervisor-Level Soft Error Detection” [8]. The author's Xu, Chiang, and Huang describe how they detect faults using a machine learning approach and a runtime detection technique in the Xen hypervisor. Instead of monitoring heartbeats or buffers, their runtime detection system utilizes fatal hardware exceptions and runtime software assertions to detect system corruptions. To detect incorrect control flow, Chiang, and Huang use a Decision Tree machine learning algorithm. They report a fault detection rate of near 99% with a low-performance overhead.[8]
6. Evaluation
Mvondo, Tchana, Lachaize, et al. performed an extensive evaluation of their FT solution. They compared their modifications (categorized into corse-grained and fine-grained solutions) with the vanilla Xen hypervisor, which provides little FT against pVM failures. It is also compared to other FT solutions: Xoar [5] and TFD-Xen [7]. The latter only handles net_uk failures [1].
The different unikernels introduce some overhead to the system. Each unikernel instance uses about 500MB of memory. While running the system without any faults occurring, the PpVMM architecture is about 1–3% slower than the vanilla Xen implementation for I/O-intensive applications [1].
First, the robustness and performance of the different NIC driver and NetBack FT solutions are discussed: Vanilla Xen is not able to complete in case of a failure in those components. The fine-grained solution PpVMM solution is up to 3.6 times faster for detection and 1.4 times faster for repair times, compared to coarse-grained approaches (like the disaggregated pVM or TFD-Xen). However, TFD-Xen is able to recover faster than this solution but also requires physical backup NICs, which results in resource waste. The shadow driver approach also prevents packet losses by buffering failed packages. Such losses may lead to broken TCP sessions in the other solutions. While providing their robustness approaches, TFD-Xen has the most throughput, followed by the fine-grained PpVMM solution. The coarse-grained PpVMM approach performs worse, and Xoar is least efficient. Those numbers can be seen in Table 2, which shows the duration of the different FT approaches took to detect and recover from a NIC driver fault. With regards to the overhead, the pVM solution, as well as TFD-Xen, introduce significant overhead in latencies due to the periodic communication with the VMM [1].
 Table 2: Benchmark results by Mvondo, Tchana, Lachaize, et al. to evaluate the robustness of the different FT solutions. A NIC driver fault was injected while executing a benchmark. The detection time (in milliseconds), recovery time (in seconds) and lost packets were recorded and listed in this table. The fastest approach to detect a fault (in 27.27 milliseconds) and recover without loosing any packets, was the fine-grained FT solution by . The quickstest recovery with only 0.8 seconds, was achieved by the Xoar project . Fault Detection Time (ms) Fault Recovery Time (s) Lost Packets Fine-grained FT 27.27 4.7 0 Corase-grained FT 98.2 6.9 425,866 TFD-Xen 102.1 0.8 2379 Xoar 52,000 6.9 1,870,921
Table 2: Benchmark results by Mvondo, Tchana, Lachaize, et al. to evaluate the robustness of the different FT solutions. A NIC driver fault was injected while executing a benchmark. The detection time (in milliseconds), recovery time (in seconds) and lost packets were recorded and listed in this table. The fastest approach to detect a fault (in 27.27 milliseconds) and recover without loosing any packets, was the fine-grained FT solution by . The quickstest recovery with only 0.8 seconds, was achieved by the Xoar project . Fault Detection Time (ms) Fault Recovery Time (s) Lost Packets Fine-grained FT 27.27 4.7 0 Corase-grained FT 98.2 6.9 425,866 TFD-Xen 102.1 0.8 2379 Xoar 52,000 6.9 1,870,921
Injecting a fault into the XenStore component during VM creation fails with the vanilla Xen and Xoar approach. In contrast, the disaggregated pVM solution completes this operation successfully and takes less time to detect crashes and data corruption. However, this solution introduces an overhead of about 20% more time because of the synchronization between the XenStore replicas. Xoar, on the other hand, not only takes longer to detect failures but also introduces an increased overhead [1].
The tool_uk unikernel introduces no overhead when it is not used, and no failure occurs. In case a failure happens during the VM migration process, vanilla Xen and Xoar both stop the migration, but the original VM, as well as the replica or new VM, keep running. This results in an inconsistent state that wastes resources because both VMs keep running [1].
Mvondo, Tchana, Lachaize, et al. also benchmarked the case when all components crash at the same time: While the PpVMM approach restores all components in about 15 seconds with a downtime of 8 seconds, vanilla Xen and TFD-Xen are not able to. Xoar also handles such failure, but with a higher overhead [1].
The scheduling optimizations, mentioned in Section 4 significantly improved the performance: On average, crashes are detected 5% faster, and the usage of implicit heartbeats decreased the CPU time by 13% [1].
7. Discussion
The disaggregation of monolithic systems into functionality-specific microservices is a strategy commonly used in cloud applications. There are multiple advantages over a monolithic system, like improved security, fault tolerance, and resilience, as was shown in the previous sections.
The benchmarks, presented in Section 6, showed promising results. The architecture by Mvondo, Tchana, Lachaize, et al. introduces little overhead but significantly improves the FT [1]. While related research uses similar approaches, the combination of the disaggregation into separate unikernels and component-specific FT logic results in significantly improved FT.
However, the presented approach is based on the assumption that the hypervisor itself functions properly and is reliable [1]. While this might be true to some extent, thanks to state-of-the-art techniques, no measure can guarantee a 100% reliability. Further research could evaluate this approach under the assumption that the hypervisor will fail eventually. A complete FT solution could work even more reliable and performant when looking at the FT of the whole solution (VMM, pVM and guest VMs).
While Mvondo, Tchana, Lachaize, et al. explains the modifications of most unikernels in great detail, the disk_uk unikernel is not described at all. However, it is stated that the implementation is similar to net_uk and therefore, and due to space reasons, left out [1]. So one can only assume that it also uses a shared ring buffer index and timestamp of the requests to detect faults. It was also not evaluated, or the results of its evaluation were not presented.
While the figures and schematics in the original paper are very well made and clear, they mention one more unikernel. The so-called “UKmonitor” unikernel is not described in the text of the paper [1] itself. However, when analyzing the figures, it becomes apparent that this is the component that runs the feedback loop and monitors the drivers.
8. Conclusion
Most modern web services already use CC technologies to realize an architecture that is elastic, scalable, and available. These technologies often run on VMs that are virtualized and managed by VMMs. The pVM approach is a commonly used technique to make the VMM more lightweight, secure, and fault-tolerant. This makes the pVM the main weakness in terms of FT. Existing solutions introduce more overhead and take longer to detect or recover from faults. The novel approach by Mvondo, Tchana, Lachaize, et al. [1] , called “Phoenix pVM-based VMM (PpVMM)”, achieves high resilience with low overhead by disaggregating the pVM into different unikernels. This improves the security and FT because of the additional isolation and explicit dependencies. Each component also includes specialized FT logic to improve its resilience. Global measures will handle the failure of multiple or even all components at the same time. The promising benchmark results provide an empirical demonstration of how well this system handles typical faults. This makes the PpVMM approach a great solution for hypervisors that power the internet as we know it.
References
[1] D. Mvondo, A. Tchana, R. Lachaize, D. Hagimont, and N. de Palma, “Fine-grained fault tolerance for resilient pVM-based virtual machine monitors,” in 2020 50th Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN), IEEE, 2020, pp. 197–208, ISBN: 978–1–7281–5809–9.
[2] Gartner. (2021). Gartner forecasts worldwide public cloud end-user spending to grow 23% in 2021: Cloud spending driven by emerging technologies becoming mainstream, [Online]. Available here.
[3] P. M. Mell and T. Grance, The NIST definition of cloud computing, Gaithersburg, MD, 2011.
[4] F. Cerveira, R. Barbosa, and H. Madeira, “Experience report: On the impact of software faults in the privileged virtual machine,” in 2017 IEEE 28th International Symposium on Software Reliability Engineering (ISSRE), IEEE, 2017, pp. 136–145, isbn: 978–1–5386–0941–5.
[5] P. Colp, M. Nanavati, J. Zhu, W. Aiello, G. Coker, T. Deegan, P. Loscocco, and A. Warfield, “Breaking up is hard to do,” in Proceedings of the Twenty-Third ACM Symposium on Operating Systems Principles — SOSP ’11, T. Wobber and P. Druschel, Eds., ACM Press, 2011, p. 189, ISBN: 9781450309776.
[6] M. M. Swift, M. Annamalai, B. N. Bershad, and H. M. Levy, “Recovering device drivers,” ACM Transactions on Computer Systems, vol. 24, no. 4, pp. 333–360, 2006.
[7] H. Jo, H. Kim, J.-W. Jang, J. Lee, and S. Maeng, “Transparent fault tolerance of device drivers for virtual machines,” IEEE Transactions on Computers, vol. 59, no. 11, pp. 1466–1479, 2010.
[8] X. Xu, R. C. Chiang, and H. H. Huang, “Xentry: Hypervisor-level soft error detection,” in 2014 43rd International Conference on Parallel Processing, IEEE, 2014, pp. 341–350, ISBN: 978–1–4799–5618–0




